|
|
|
I have a new website: link (you should be redirected automatically). |
|
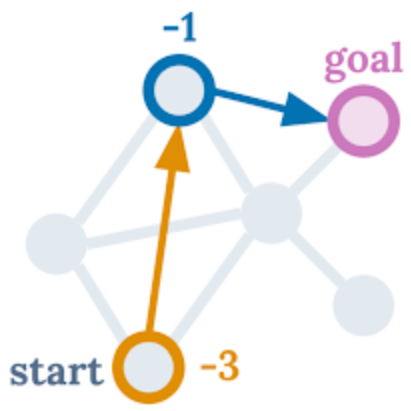
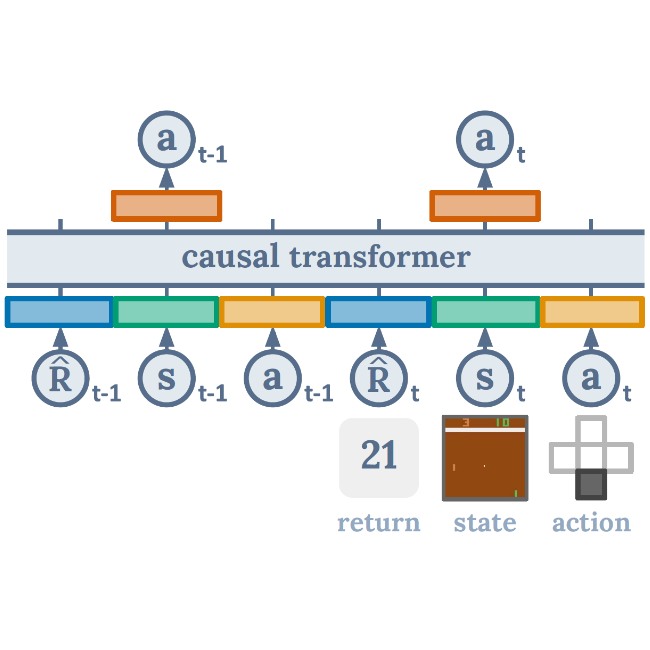
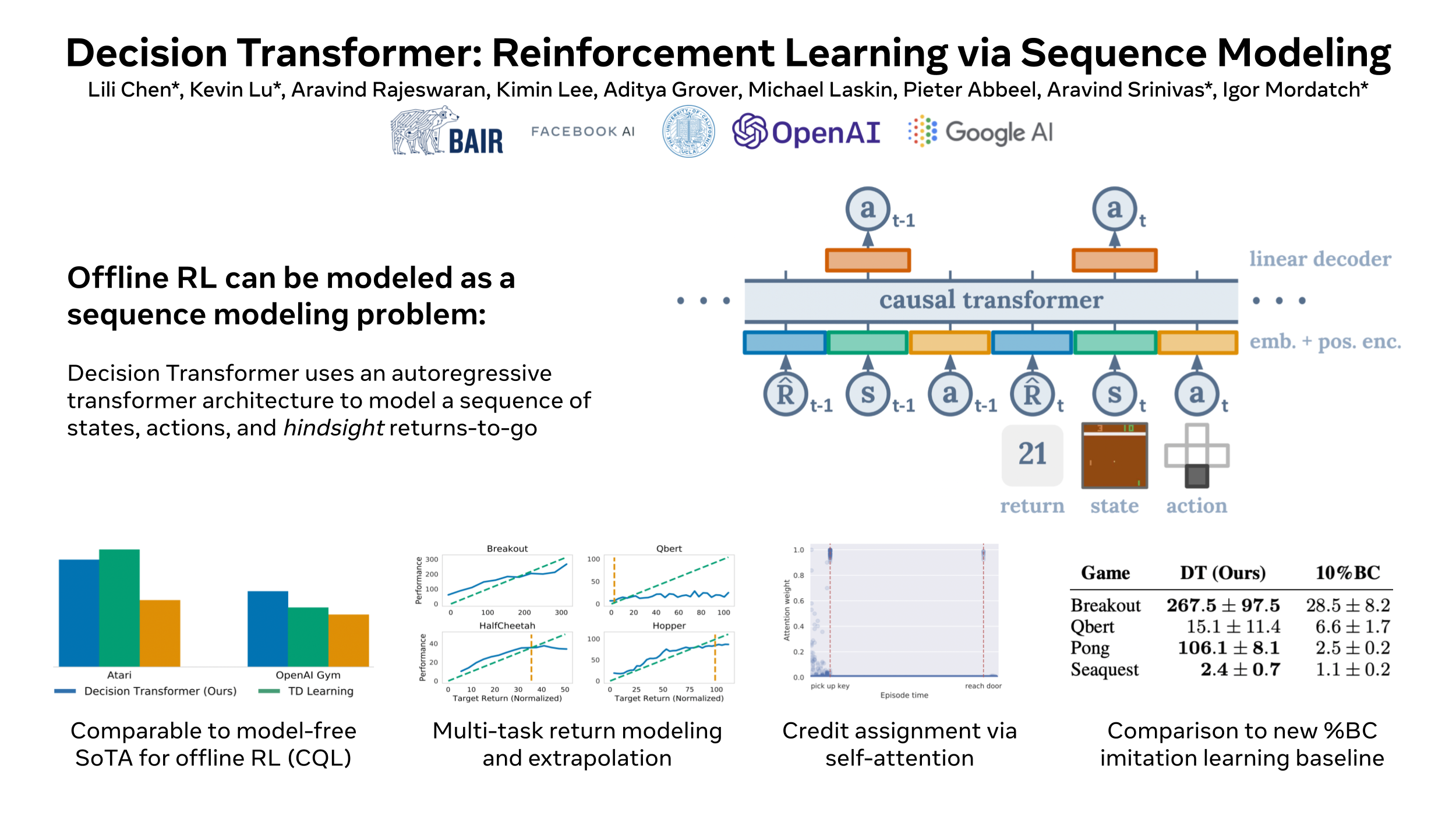
Lili Chen*, Kevin Lu*, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas*, Igor Mordatch* Neural Information Processing Systems (NeurIPS), 2021 Official: arXiv / website / poster / tweet / code Press: The Batch article / SyncedReview article / The Gradient article / Yannic Kilcher video / Eindhoven RL seminar |
|
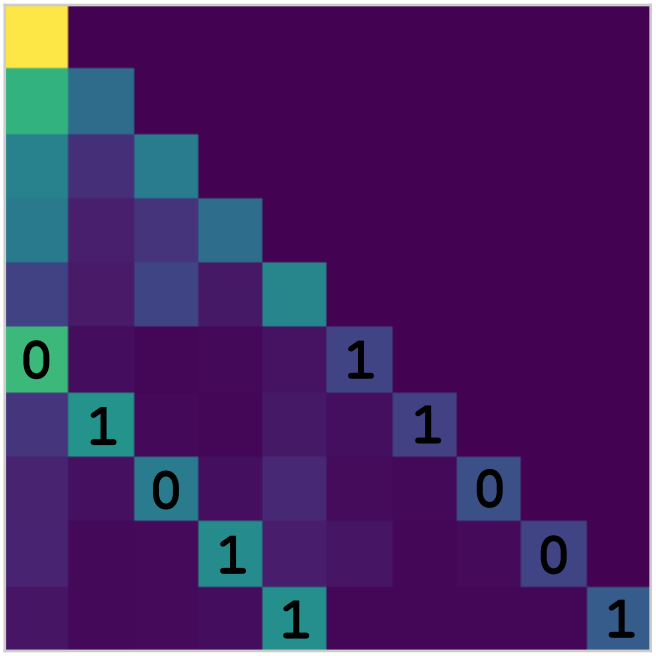
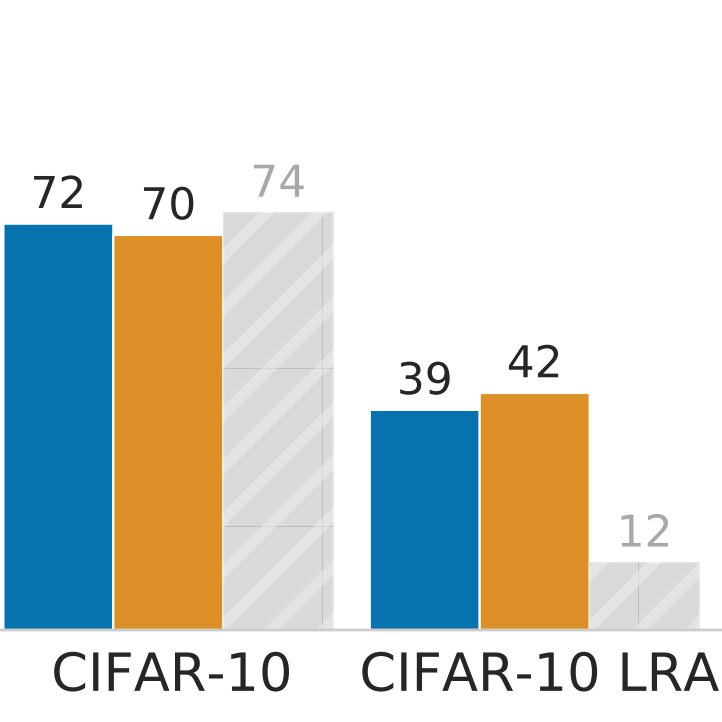
Kevin Lu, Aditya Grover, Pieter Abbeel, Igor Mordatch AAAI Conference on Artificial Intelligence, 2022 Official: arXiv / blog / poster / tweet / code Press: The Batch article / VentureBeat article / TWIML podcast / Yannic Kilcher video |
{kind=link}
|
Back when I was a TA at Berkeley, I wrote a study guide for our course on Probability and Random Processes. |
|
|